Should I use PCA before k-means?
First do PCA analysis. Determine the number of unique groups (clusters) based on PCA results (e.g., using the "elbow" method, or alternatively, the number of components that explains 80 to 90% of total variance). After determining the number of clusters, apply k-means clustering to do the classification.
Should PCA be done before clustering?
In short, using PCA before K-means clustering reduces dimensions and decrease computation cost. On the other hand, its performance depends on the distribution of a data set and the correlation of features.So if you need to cluster data based on many features, using PCA before clustering is very reasonable.When should PCA be used?
PCA should be used mainly for variables which are strongly correlated. If the relationship is weak between variables, PCA does not work well to reduce data. Refer to the correlation matrix to determine. In general, if most of the correlation coefficients are smaller than 0.3, PCA will not help.Where should you not use PCA?
While it is technically possible to use PCA on discrete variables, or categorical variables that have been one hot encoded variables, you should not. Simply put, if your variables don't belong on a coordinate plane, then do not apply PCA to them.What is the importance of using PCA before the clustering choose the most complete answer?
PCA helps your to find latent features among all your data, can reduce your dimensionality for 1/10, making easier to visualize data and faster training because uses less hardware to run.Unsupervised Learning | PCA and Clustering | Data Science with Marco
What are the disadvantages of PCA?
Disadvantages of PCA:
- Low interpretability of principal components. Principal components are linear combinations of the features from the original data, but they are not as easy to interpret. ...
- The trade-off between information loss and dimensionality reduction.
What is one drawback of using PCA to reduce the dimensionality of a dataset?
You cannot run your algorithm on all the features as it will reduce the performance of your algorithm and it will not be easy to visualize that many features in any kind of graph. So, you MUST reduce the number of features in your dataset.Is PCA always necessary?
1) It assumes linear relationship between variables. 2) The components are much harder to interpret than the original data. If the limitations outweigh the benefit, one should not use it; hence, pca should not always be used.What is the relationship between K means clustering and PCA?
k-means tries to find the least-squares partition of the data. PCA finds the least-squares cluster membership vector. The first Eigenvector has the largest variance, therefore splitting on this vector (which resembles cluster membership, not input data coordinates!) means maximizing between cluster variance.Does PCA reduce accuracy?
Using PCA can lose some spatial information which is important for classification, so the classification accuracy decreases.Does PCA improve accuracy?
Conclusion. Principal Component Analysis (PCA) is very useful to speed up the computation by reducing the dimensionality of the data. Plus, when you have high dimensionality with high correlated variable of one another, the PCA can improve the accuracy of classification model.What type of data is good for PCA?
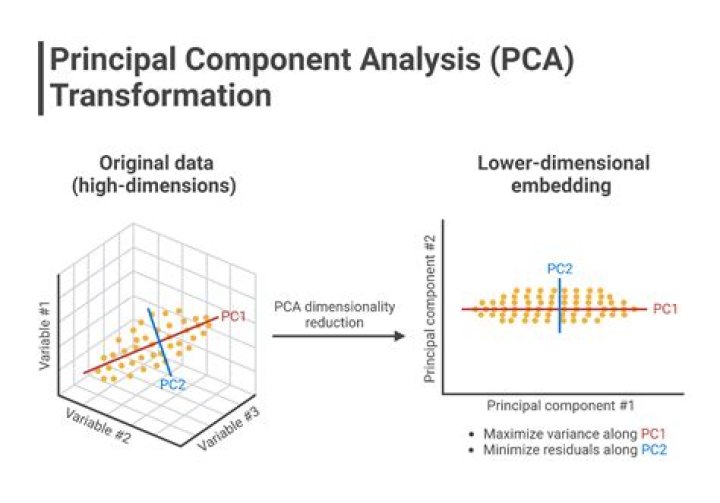
PCA works best on data set having 3 or higher dimensions. Because, with higher dimensions, it becomes increasingly difficult to make interpretations from the resultant cloud of data. PCA is applied on a data set with numeric variables. PCA is a tool which helps to produce better visualizations of high dimensional data.Is it necessary to scale data before PCA?
PCA is affected by scale, so you need to scale the features in your data before applying PCA. Use StandardScaler from Scikit Learn to standardize the dataset features onto unit scale (mean = 0 and standard deviation = 1) which is a requirement for the optimal performance of many Machine Learning algorithms.How do you cluster after PCA?
To better understand the magic of PCA, let's dive right in and see how I did it with my dataset in three basic steps.
- Step 1: Reduce Dimensionality. ...
- Step 2: Find the Clusters. ...
- Step 3: Visualize and Interpret the Clusters.
How do I choose K for PCA?
1 Answer
- Run PCA for the largest acceptable K on training set,
- Plot, or prepare (k, variance) on validation set,
- Select the k that gives the minimum acceptable variance, e.g. 90% or 99%.


